专用向量数据库并非新惹事物,如Milvus等,它们早已问世,并主要被想象用于非结构化多模态数据的高效检索。这类数据库舒服了诸如以图搜图(雷同于淘宝的拍立淘功能)、以音搜音(雷同音乐识别应用Shazam)以及用视频搜视频等特定需求。同期,PostgreSQL生态系统中的pgvector、pase等插件也提供了雷同的功能。有关词,尽管这些期间在特定领域内有一定的应用,但由于其相对小众的需求,永恒以来并未引起平庸的关爱。
向量数据库爆火“缘故”
有关词,跟着OpenAI过甚ChatGPT等大型言语模子的出现,这一切发生了天崩地裂的变化。这些先进的AI模子展现出了对多种体式文本、图片和音视频的真切结识才智,何况好像将它们长入编码为交流维度的向量。这一革新的蹙迫性在于,它使得向量数据库在存储和检索这些AI大模子生成的镶嵌向量(embedding)方面证实了至关蹙迫的作用。
具体来说,大型言语模子如ChatGPT通过深度学习期间,将不同模态的数据(文本、图像、音视频等)滚动为高维空间的向量暗示。这些向量捕捉了数据的内在特征和语义信息,使得不异数据在向量空间中的距离更近。向量数据库,如Milvus,则提供了高效存储和查询这些向量的才智。它们应用近似最隔邻搜索(ANN)等算法,在海量数据中快速找到与查询向量最不异的后果。
因此,OpenAI/ChatGPT等期间的兴起不仅改换了咱们对AI才智的默契,还极地面激动了向量数据库的应用和发展。如今,这些正本小众的向量数据库正镇静成为复古AI应用的蹙迫基础门径,助力达成愈加智能和高效的数据检索与分析。
向量数据库在本年的科技波浪中迎来了一个显耀的增长节点,具体在3月23日,当OpenAI发布chatgpt-retrieval-plugin名堂时,推选将向量数据库动作增强ChatGPT插件“永恒操心”功能的要津组件。自此之后,无论是在Google Trends的搜索热度上,照旧在Github的Star数目上,向量数据库名堂齐呈现出爆发式的增长态势。与此同期,千里寂了一段时辰的数据库投资领域也迎来了新的期许,Pinecone、Qdrant、Weaviate等“专用向量数据库”公司纷纷崭露头角,竞相融资数亿,唯恐错过这场AI期间基础门径设备的盛宴。
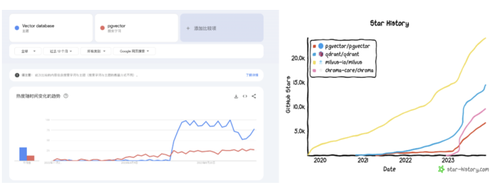
Google Trens 与 Github Star
与此同期,数据库领域在投资领域千里寂了一段时辰后,又迎来了一波小阳春 —— Pinecone,Qdrant,Weaviate 诸如斯类的“专用向量数据库”冒了出来,几亿几亿的融钱,只怕错过了这趟 AI 期间的基础门径快车。

向量数据库生态全景图
有关词,这股向量数据库的狂热波浪终究难逃剧烈波动的荣幸。其激越的势头在短短半年内便赶紧降温,时局发生了天崩地裂的变化。如今,除了少数二线厂商仍在追逐末班车,试图通过软文营销来招引眼球,一经鲜少有东谈主再热衷于炒作专用向量数据库这一话题,夙昔的飞腾已逐渐恐慌。
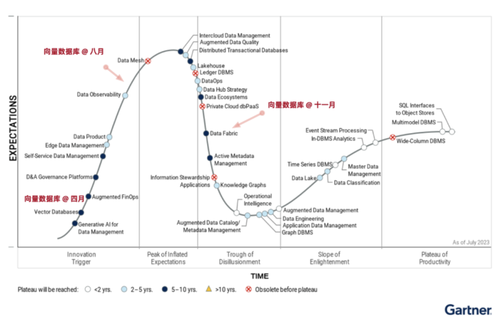
向量数据库:的确需求照旧伪需求?
在商议向量数据库是否为伪需求时,咱们最初要坚忍到向量的存储与检索是AI发展中一个的确且不休增长的需求。有关词,这并不虞味着专用的向量数据库是舒服这一需求的势必选拔。
专用向量数据库的局限性:早期的专用向量数据库如Pinecone、Weaviate等,天然在经管AI模子操心才智不足的问题上有所孝顺,但跟着AI期间的杰出,尤其是GPT-4等模子障碍文处理才智的显耀擢升,这些数据库的作用镇静松开。
GPTs 将 AI 的易用性提高到一个全新的档次
OpenAI GPTs功能的冲击:OpenAI推出的GPTs功能为中小学问库场景提供了齐全的“操心”与“学问库”经管决策,进一步挤压了专用向量数据库的市集空间。用户无需建设复杂的向量数据库,只需上传学问文献并编写领导词,即可快速设备出AI Agent。
经典数据库的向量推广:与此同期,PostgreSQL、Redis等经典数据库系统纷纷推出了向量推广功能,这些推广不仅性能富厚可靠,而且与现存系统无缝集成。用户无需引入新的专用向量数据库系统,即可平静达成向量数据的存储与检索。
期间门槛与开源库的应用:尽管数据库系统自己具有一定的期间门槛,但向量数据处理的期间门槛相对较低。进修的开源库如FAISS、SCANN等一经宽裕舒服大多量场景的需求。关于大厂来说,应用这些开源库达成向量数据处理功能既通俗又高效,无需特别引入专用向量数据库系统。
尽管向量的存储与检索是的确需求,但专用向量数据库并非舒服这一需求的独一路线。跟着AI期间的杰出和经典数据库的向量推广功能的推出,专用向量数据库的市集空间将受到进一步压缩。因此,从逻辑性和了了度的角度来看,咱们不错以为专用向量数据库在一定进程上是一个伪需求。
专用向量数据库堕入了一个死局之中:小需求 OpenAI 躬行下场经管了,步伐需求被加装向量推广的现存进修数据库霸占,超大需求也简直没什么达成的门槛。留给专用向量数据库的生态位也许能足以支握一家专用向量数据库内核厂商活下来,但想作念成一个产业是不行能了。
通用数据库与专用向量数据库的比较
在筹议通用数据库与专用向量数据库时,咱们最初要明确一个及格的向量数据库不仅应具备向量的存储与检索才智,还需舒服数据库的基本步伐和条目。有关词,从市集近况来看,通用数据库与专用向量数据库之间存在显耀的各别。笔者在采访中也听到了繁多用户和设备者的声息。
通用数据库,如PostgreSQL,流程数十年的发展,一经格外进修和完善。它们支握多种数据类型、提供备份/收复机制、高可用性等要津功能,并通过数百万行的代码经管了数据库领域的复杂问题。
比拟之下,专用向量数据库的想象则显得相对通俗。尽管它们专注于向量的存储与检索,但从期间门槛的角度来看,向量部分的达成难度远低于通用数据库。以pgvector为例,这个基于PostgreSQL的向量数据库推广仅用不到两千行代码就经管了向量问题,这突显了向量与数据库之间复杂度的巨大各别。
专用向量数据库的简化想象也激发了一些质疑。举例有些用户暗示,由于它们过于专注于向量功能,频频忽略了数据库的其他要津特质,如数据类型各样性、备份收复机制等。这种简化想象可能导致在实质应用中面对诸多阻抑和挑战。
从期间门槛的角度来看,达成一个专用向量数据库可能并不需要深厚的数据库专科学问。基本的数组数据结构、排序算法和向量点积盘算推算等学问点关于稍有编程教导的本科生来说并不生分。因此,专用向量数据库的期间门槛相对较低,难以变成独有的竞争上风。
pgvector与Pinecone:通用与专用向量数据库的较量
在向量数据库领域,pgvector与Pinecone的对比突显了通用与专用数据库之间的显耀各别。pgvector动作PostgreSQL的向量推广,不仅功能强盛,而且正在赶紧占领市集。而Pinecone,虽动作专用向量数据库SaaS的杰出人物,却在多个要津维度上显闪现不足。
最初,性能方面,Pinecone引以为傲的高性能在实质测试中却不足pgvector。在Supabase的测试案例中,pgvector在蔓延发扬、总体隐晦以及资本上均优于Pinecone,这径直挑战了专用向量数据库的性能传闻。实质上,在AI应用中,向量检索的性能频频并非决定性身分,因为模子推理的支出频频远超向量检索。
其次,易用性上,Pinecone的专用Python API与pgvector的通用SQL Interface各有优劣,但实在的挑战在于混杂检索的需求。在实质应用中,咱们频频需要谀媚向量检索与干系型数据库的元数据来进行详尽查询,这时pgvector的SQL接口无疑更具上风。Pinecone天然支握附加元数据,但基于API的想象使其推广性和可珍重性受限。
更蹙迫的是,Pinecone在数据库基础功能方面存在彰着不足,如备份/收复/高可用、批量更新/查询操作、事务/ACID等,这些功能关于坐褥环境至关蹙迫。此外,Pinecone在调回率与反映速率之间的衡量上也显得过于通俗,穷乏纯真性。
与此同期,pgvector等通用数据库加装向量功能的决策,不仅资本更低,而且功能更全面、性能更富厚。这些通用数据库一经领有宏大的用户基础和进修的生态系统,加装向量功能后好像赶紧舒服市集需求。
因此,尽管向量的存储与检索是AI期间的蹙迫需求,但专用向量数据库的市集出息并不乐不雅。pgvector等通用数据库的崛起一经预示着专用向量数据库的衰退。关于寻求富厚、可靠经管决策的用户来说,选拔pgvector等通用数据库加装向量功能的决策无疑是聪敏之举。